

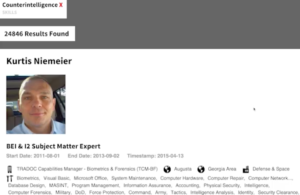
M.C. McGrath

Targeted Individuals: Intelligence Community mercenaries exposed via the ICWatch program (2015-2022) are certainly among the most highly trained (and demonic) of our stalkers and attackers.
“*Cryptocracy:” (“Rule By Secrecy”); “Spookocracy” (Rule by Spies), aka “The Hidden Hand”* (See Part D below for further explanation)
History of ICWatch (from Wikipedia)
ICWATCH launched on May 6, 2015;[12] on the same day, Transparency Toolkit, the group that created ICWATCH, presented it at the re:publica conference.[3] At launch, the database contained information from over 27,000 LinkedIn profiles.[3][13]
By mid-May 2015, Transparency Toolkit began receiving requests from individuals to be removed from ICWATCH, including death threats.[14] Following the threats as well as distributed denial-of-service attacks made against the site, WikiLeaks began hosting the website and database by the end of May 2015.[14][15]
In August 2016 TechCrunch reported that LinkedIn was suing 100 unnamed individuals who had scraped LinkedIn’s website, and named ICWATCH as a possible target.[16]
As of February 2017, the database tracks over 100,000 profiles from LinkedIn, Indeed, and other public sources.[17]
In November 2022, ICWATCH and other datasets became unavailable on the WikiLeaks website.[18][19]
Epigraph quotes:
1) “My goal in this (ICWatch) is to provide a face to the surveillance state. Not everyone (on this list of 27,000 as of 2015) is working on secret surveillance programs, but a significant majority of the people in the data base are….. What was most surprising to me was that there are a lot of people (mercenary covert intel operators) who are not just talking about surveillance programs, but they’re talking about being involved in deciding who to kill and in killing people and in torturing people.”
M.C. McGrath, from: Watching the Watchers and Tracking Spies (I and II) videos below
2) “I dared to challenge them and they sent an army after me…. The “New World Order” boys. I call them the “Junior High Boys.” They recruit them out of Special Forces….”
Ted Gunderson, Ex-high ranking FBI Section Chief, Whistleblower & TI (from: Appendix 211: Former FBI Section Chief and TI, Ted Gunderson: ‘Targeted Individual Program’ Is ‘Satanic (Illuminati*), Illegal, US Government Rogue, Criminal Enterprise” (lecture video w/ my notes)
3) “George W. Bush said that in the War on Terror, the whole world is the battlefield. They weren’t joking. Their plan was to have the ability to target any person on the planet in real time. And that is what they have been doing ever since. Today, they are not just targeting political dissidents, or journalists, they are targeting child abuse victims with pending claims against the government, and earth quake insurance claimants. This spying and targeting by government agencies is all paid for by taxpayer dollars.
The intelligence systems are part of what is known as the “military kill chain.” The “kill chain” is completely dependent on the intelligence systems. This same system is being used domestically against innocent civilians…. It is at the discretion of the government as to what qualifies as a threat to national security. There is no definition of threat to national security on the lawbooks. It is a completely arbitrary term that is arbitrarily applied. It comes down to what they think about you and your activities.
They want to expand the targeting program to be able target classes of people, or locations instead of people, or networks instead of people. In essence, this is a general warrant. The use of general warrants was one of the causes of the American Revolution. It’s about classifying people and grouping people.
They need more targets because they are integrating private for-profit surveillance and intelligence agencies into the Global Network. Just like Donald Rumsfeld introduced the Total Force doctrine, indemnifying private agencies from legal retribution. There is now a profit motivation for targeting large numbers of people. So we will see this phenomenon of people being targeted by the state will grow exponentially. The capacity is there for it to become everyone. The for-profit model demands it. They could grow to include the entire civilian population as their targets. The NSA hands over whole data bases to their “customers.”
Suzie Dawson, New Zealand activist, politician, journalist and targeted individual (The NSA Global Spy Network: Episode 1: Opening the Five Eyes: Exposing the Spies – Suzie Dawson (9/22/19); Transcription & Graphics).
4) Comment from @metoo924 To M.C. McGrath’s Tracking Spies video below (6 years ago (edited))
I know that patriots fought for this country so that you have the right to create these type of programs, but do you not realize that you are capitalizing on people who protect you and protect the US everyday? They do it behind closed doors, in locked down buildings, in places you will never go. But rest assured, even when you reveal who they are, show their homes and families (THAT IS JUST IRRESPONSIBLE), they will continue to protect America’s interest**. It makes me sick to know that you are ‘outing’ them like this… Why? They protect you and your family, why won’t you protect them and their families?
Webmaster Introduction:
M.C. McGrath is a young “hacktavist” (computer hacker/activist) who, in a 2015 project entitled ICWatch (Intelligence Community Watch), recovered and posted the resumes of over 27,000 former military, intelligence, and special forces operatives from their online LinkedIn profiles. These ex-military and intelligence personnel advertised their counterterrorism, sabotage, and organized stalking-electronic torture black ops experience and skills to thousands of government and non-government agencies and private companies in hopes of personally profiting from the phony “War on Terrorism” (actually, “War Of Terrorism”). Due to the limited scope of the ICWatch project, the actual number of such highly-trained, mercenary spies and killers cum gangstalking perpetrators in America could be one or two orders of magnitude greater than 27,000 (or between 270,000 and 2.7 million). And if we factor in the DHS-FBI-police “domestic national security force,” i.e., citizen-stalkers, citizen-spies, informants, surveillance role players, spotters, trackers, crisis actors, police informants, citizen-based agents, contract stalkers, Neighborhood Nazis, etc., the number could even be three or four orders of magnitude greater (or 27 to 270 million). At any rate, by 2017, the list of profiled spooks on ICWatch had expanded to over 100,000 and by 2022, the list was removed from the internet.
It is ironic that M.C. McGrath’s computer-sleuthing project itself was funded by Palantir’s founder, Peter Thiel, and his Thiel Fellowship. This is ironic because Palantir tracks and traces “suspected terrorist threats” (government euphemism for FBI-DHS-black-listed “truth tellers,” activists, whistleblowers, enemies of the state, and “dissidents”) in this massive domestic terrorism black operation. Does McGrath’s work, then, constitute “controlled opposition?” Or is Thiel, who is Jewish, observing some Jewish/Luciferian mandate that “they have to tell us what they are doing to us?” At any rate, in regards to Palantir, see (from this website):
2) NSA’s ECHELON, PRISM, XKEYSCORE, & PALANTIR Surveillance-Tracking-Targeting Programs
We need to recall that in “9/11 Synthetic Terror: Made in U.S.A.” (2005), Dr. Webster Tarpley notes that domestic terror events (black ops) such as 9/11 are staged using the following personnel-structural components:
1) moles (for example, including VP Dick Cheney, DOD director, Donald Rumsfeld, the PNAC “neocons” etc. for Operation 9/11)
2) patsies (for example, Osama Bin Laden and the 19 alleged hijackers in Operation 9/11)
3) professional killers (including Special Forces, ex-military, mafia, SIGREDUX (Signature Reduction), CIA, NSA, DHS, FBI, etc. in both Operation 9/11 and in ongoing organized stalking-electronic harassment terror-torture-murder ops)
Thus, organized stalking-electronic torture, like 9/11 itself, is a staged, domestic terrorism (black) operation that deploys this same basic structure of operatives.
McGrath’s work is mentioned by New Zealand activist, politician, journalist and TI, Suzie Dawson in her 10-part series, “Opening the Five Eyes, Exposing the Spies;” for example in: Episode 2. Opening The Five Eyes: Exposing The Spies; Suzie Dawson (9/29/19) w/ Transcription, Graphics, & Perp CV’s.
Below are six short videos by McGrath (Part A) as well as text from an interview with him (Part B).
Some comments in Part C below seem to have been written by these same covert intel operators/contractor spies-for-hire, now going under the re-branded names of “cyber-stalkers,” “cyber-terrorists,” “computer network operations specialists,” Interactive Internet Activities” (IIA) operatives, etc. I.e., they are trolls. As a TI, it is clear to me while these individuals may believe that they are “patriots who fight for our country,” they are the real domestic terrorists. In contravention of virtually all America’s laws and everything it stands for, these traitors, whores, cowards, bullies, thugs, killers, psychopaths, losers, and scum are carrying out the torture and murder of innocent American citizens. They should be tortured and hung for these crimes against humanity (torture, murder, attempted murder, treason).
Part A: Videos Explaining M.C. McGrath’s work
I. 2015 – M. C. McGrath: Watching the Watchers: Building a Sousveillance State
Representative Graphics from I. 2015 – M. C. McGrath: Watching the Watchers: Building a Sousveillance State





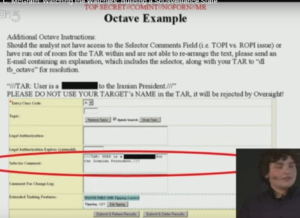
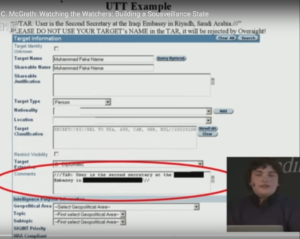











II. Tracking Spies W/ M.C. McGrath
III. Watching The Watchers
https://exposingtheinvisible.org/en/films/mc-mcgrath-watching-the-watchers/
Graphics from III. Watching the Watchers







IV. Exposing the Invisible
https://www.exposingtheinvisible.org/en/films/collections/mc-mcgrath/
V. The Making of IC (Intelligence Community) Watch
https://exposingtheinvisible.org/en/films/mc-mcgrath-makingof
VI. IC Watch: Using the Tool
IC Watch: Using the tool
Graphics From VI. Using The Tool

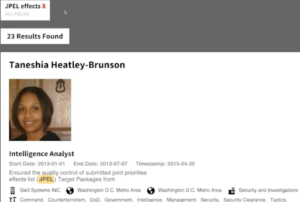
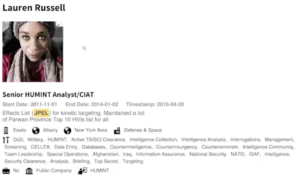
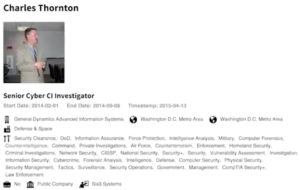
VII. Accidental leaking and other types of open data
Accidental leaking and other types of open data
Part B: M.C. McGrath, IC (Intelligence Community) Watch, and the Transparancy Toolkit. Text of Interview with M.C. McGrath
M.C. McGrath is a hacker and an activist based in Berlin, Germany and is the creator of Transparency Toolkit. This Toolkit provides a set of tools to collect data from various open data sources. McGrath also created ICWATCH, a database of an estimated 27,000 LinkedIn resumes of people who work in the intelligence sector. He uses this database to find information about the intelligence community, surveillance programmes and other information that is very much private but that has been posted publicly via the professional networking platform, LinkedIn. In this interview we talk about the processes and reactions to both Transparency Toolkit and ICWATCH, different types of open data and why he believes holding the individual to account is important.
The interview with M.C. has been divided into five videos.
Watching the Watchers* looks at how M.C. uses open data to understand the intelligence sector.
The Making of IC Watch focuses on the processes and methodology behind making ICWATCH.
M.C. proposes three ways of understanding open data in Accidental Leaking and Other Types of Open Data.
The fourth video looks at tips and techniques for activists to be safer online inActivists on Online Activity.
Lastly a video of M.C. Using the tool ICWATCH.
The interview can be read below in its entirety.
Before you conceived of the idea behind Transparency Toolkit, what other projects did you work on?
I went through a few different projects in this space before I came to Transparency Toolkit. Four years ago, I started very actively working on various small projects in this space. I finally decided I was fed up and wanted to do something. The first thing I did was plan a protest of the WikiLeaks grand jury investigation, I got together a bunch of friends but afterwards that we thought “Oh, we’re a bunch of computer science students, why don’t we do something technical and why don’t we try to make software?”
So I started taking a bunch of classes in the Civic Media, a group with MIT Media lab and doing research. One of the things I did was to make this project called Leaks Wiki, where I interviewed a bunch of people involved in leaking websites and investigative journalism about the processes that they had in their work. How they got data, what they did to process the data and how they released it and what they have found most effective and what challenges they had. I worked on a number of things, for example, ways to pull different documents into timelines to make them easier to browse and different collaborative investigation and decision-making systems.
Then when I moved onto working on crowd-sourcing and collaborative investigations and looking into that. I had this very broad idea for something that would help people, manage collaborative investigations and provide analytical tools and it was way too big and way too broad. So then over the next year, I stared paring that down. I thought, “Oh now I can make analytic software for journalists and that’s a good way to start.” Then from there, I was just sitting next to someone at some point and he was googling ‘XKeyscore’ and I saw a bunch of LinkedIn profiles coming up. I thought, “Ah, we can start collecting this data on an automated way” and then I started making network graphs showing which companies help which programmes.
I started to realise how many other open data sources were just available to everyone, freely online and how much secret information was in them. I kept making analytic software but I started focusing just on those data sources and how we could use them to expose secrets, to expose human rights abuses and other things that people would want to be hidden but are inadvertently revealing details about online.
Why were you interested in trying to help WikiLeaks as a student?
About a year before that, I had started getting interested and just following it in the news reading some of the documents, but I wasn’t actually really thinking of getting that involved. I ended up joining a hacker space at my school, called ‘BUILDS’, and I made a lot of friends there. I realised soon after that they had been caught up in the dragnet investigation of WikiLeaks because Chelsea Manning had visited for the opening party of this hacker space. Then the founder of BUILDS had gone onto found the Manning support network so he was being stopped at the border and questioned and was eventually subpoenaed to appear before the Grand Jury. So I ended up getting more and more upset as I saw people being questioned, stopped, and surveilled. This pushed me over the edge from just being interested and thinking, “Wow, this is important and it could be useful” to “Well, I need to do something about this because this is a problem.”
What was the principle idea behind Transparency Toolkit?
It changed a lot over time. There are certain things I could point to as first principles, but the reasoning behind it changed over time. The general idea behind Transparency Toolkit is that being able to understand lots of information is important, but there’s so much information available.
I was watching WikiLeaks release all this information and was thinking, it’s not really being used for as many things as it could be. I was somewhat frustrated with that. So I was thinking of tools that would help people be able to load in all this information and go through it in a way that was more effective. Then from there, I kind of stumbled upon the open data thing, which made that even more powerful.

Screenshot from the Transparency Toolkit website, taken on 27 November 2015.
What makes this kind of data, like open data or the kind of radical transparency world like WikiLeaks, more effective?
There are three main ways that people and groups can get data from governments and organisations. One of them is governments releasing them themselves, either through FOIA requests or open data initiatives, which is great and people have done a lot of great work around, but the governments can also choose what to release and spin it. So that’s important, but in some ways it’s the, weakest way.
Then, there’s leaking documents. So whistleblowers releasing documents, giving them to journalists and the media and them being released that way.
The third way is just taking advantage of the data that people and institutions leak accidentally themselves. The powerful thing about that is that people don’t explicitly decide, to release it, not even a whistleblower explicitly decides to release this information. It’s up to people to collect and make sense of it on their own. It doesn’t rely on any other entity, except for the people who are accidentally releasing it, which will always continue to happen in some fashion.
I think that’s what makes it particularly powerful, it’s completely independent of anything else and it’s not something that can be controlled or shut down because when thousands of people are posting things about the secret programmes they’re working for online, short of shutting down the sites that they are on and where those are released. Even then it would be cached to other websites. They’re not going to be able to get that information off the internet overnight. People can take it down over time. You can have policies about what people can post but it takes time, it’s not something that you can easily shut down or control.
What is Transparency Toolkit? What’s in it and how can we interact with it?
Transparency Toolkit is a set of tools to collect data from various open data sources like resumes, job listings, certain social media platforms, and other sites. Transparency Toolkit enables users to search through that data and filter through it in an easy fashion. They are also able to visualise that data and look at trends and get a higher-level overview of what’s going on and who’s involved.
Transparency Toolkit is tools for free and open-source software for open-source intelligence and surveillance. In many ways it’s using some of the same techniques that the surveillance state uses but it’s using them against the intelligence community and it’s solely based on open data.
What is ICWATCH made up of?
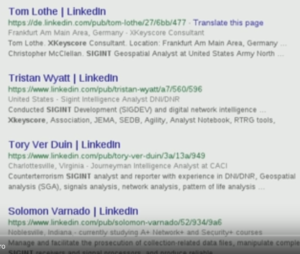
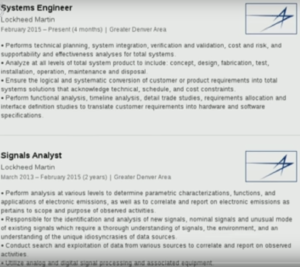
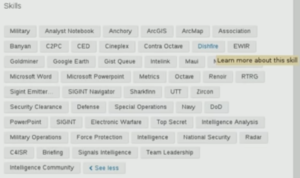
ICWATCH is a searchable collection of currently just LinkedIn profiles of people involved in the intelligence community. LinkedIn profiles, because many people mention things about their work and their job history on LinkedIn, so they say, “Oh, I know how to use Microsoft Word and XKeyscore”, just in their skills on their LinkedIn profile, and sometimes they also mention unknown code words and define them.
We’ve collected them all in one place, and made software so that anyone can search through them to better understand surveillance programmes, or which companies help with which programmes, or the career paths of people in the intelligence industry. We want to understand both the details of the programmes themselves as well as the people involved. Institutions are made up of people, and being able to understand why people get involved and, if people leave the intelligence community, why they leave and what pushes them to do so, is important for understanding how we can reform mass surveillance.
How would you describe the scale of the data that you already have in ICWATCH?
In ICWATCH we have, quite a bit of data, about 27,000 profiles of people involved in the intelligence community, primarily the US intelligence community but also some people around the world. These range from people who are saying that they work as a contractor or maybe mention some interesting terms, to people who are listing tons of secret code words on their profiles, sometimes with helpful descriptions of what the code words are.
There are still some programmes that aren’t mentioned in this data that are, perhaps, better kept secrets, but there are quite a few that are mentioned. For the programmes that many, many analysts use, like XKeyscore, you could find many mentions of them just publicly.
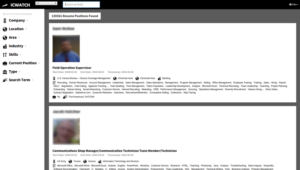
Screenshot from the ICWATCH website taken on 27 November 2015.
Why did you chose to focus on the intelligence and surveillance community in your first iteration of ICWATCH?
Intelligence and mass surveillance is something that has interested me for awhile. It’s also a particularly interesting topic, because it’s information that’s very much secret, but there’s still so much posted publicly about it. In particularly with signals intelligence, more so than other types of intelligence, there are many code words that are very clearly indicative of someone working in this; so, XKeyscore and PINWALE and all these other things. Those are very indicative and it can be filtered down by using terms like SIGINT more easily than other areas of intelligence, or other areas all together. You can very clearly say, “this person is an analyst who is looking at, intercepted communications, and doing this with it, and they’re probably focusing on this particular topic.” You can tell that from someone’s LinkedIn profile more so than many other areas. So it was very interesting for that, but I was also just interested in it, and it was shortly after the Snowden revelations when I started working on this in this sense.
What was the most difficult part of scraping, analysing and cleaning up the data?
There are different strategies for scraping data that we sort of picked up over time. Some of the code words are common terms, so if you’re searching for some common word like “PRISM,” for example, there are tons of companies that mention PRISM, that have nothing to do with a surveillance programme. There are a few people who mention it that have to do with a surveillance programme but not nearly as many.
So we had to start using filter terms like, “PRISM SIGINT” as this returns much more accurate results, than just “PRISM.” That will at least get people working in signals intelligence, and it’s often people who are mentioning PRISM as the programme, so we found some ways to filter down the results to more relevant ones. Reducing noise was one of them and we’ve got pretty good at those terms but we still have some noise in the dataset, from our early search terms.
What’s the relation between Google and LinkedIn?
When we were scraping we only collected LinkedIn public profiles. The LinkedIn public profiles aren’t searchable via LinkedIn, you have to have the URL to be able to view them, so we had to go through Google, because Google was the only search engine that had indexed them.
We did “site: linkedin.com/pub” and then with the search terms we could get a preview of the results and I would say, “Okay, this looks like it doesn’t have very much noise. I’ll add that to the list,” and then I would run that. But we had to start switching between IP addresses just to avoid getting blocked and we also had to slow down all of our tools so that we wouldn’t get blocked as well.
Why didn’t you ask LinkedIn for access to that information?
It’s faster. I didn’t ask LinkedIn for access to the information because it’s faster to collect it on my own and I’m also not sure they would give me access to it. They seem to have some interest in journalists using LinkedIn for their research and they’ve had some programmes I’ve heard of around that, but I’m not sure how they would view something like this using it in bulk, so I haven’t really spoken to them because of that.
This data you’ve collected doesn’t only show you resumes of people but also you can look at links between individuals, programmes and institutions. What kind of metadata did you find?
There’s definitely a lot of interesting metadata in this. So you can see where people worked and you can then see what programmes they worked on, then you can make a list of the companies that helped different the surveillance programmes. You can see which programmes are mentioned with each other and which programmes are mentioned with particular skills. There’s also this nice related people list on the side, which is also very useful metadata. You can’t actually see the connections of people on LinkedIn, but you can see the people also, the people that are frequently viewed along side them. Which in my experience are people they frequently know, or they work in the same company, or that they’re doing very closely related work, so that can be used as almost as a stand-in for the connections, so that’s also quite useful.
Then you can see the location of where people are. So maybe people are working on a particular programme in a particular location for a particular company and you can figure that out. Also you can find people who maybe don’t explicitly mention the programme but match similar patterns and they’re probably involved in the same thing. It’s also possible to match some of this to other data sources, which we’ve been doing manually so far, but we’ll eventually hope to do automatically.
What are your biggest “aha” moments from gathering and analysing this data?
One of the most interesting things I found was when I was first looking at the data. There was someone whose profile I picked because it had a lot of code words on it and it seemed like it would be interesting. I started writing down all the code words and trying to figure out what his work flow is and what he did. Then, I got to his latest job listing and he said something about how he was calling for external review of collection management processes. Then, after 22 years of working in the intelligence community, he left and started working as a used car salesman. I found that interesting and I didn’t realise, at that point, that I could use this to find people who had left the intelligence community, who might be upset with what had happened and something might have pushed them to leave. But then I realised, “Oh wow, this is interesting. We can use this to figure out why people left the intelligence community, what they do afterwards, what pushes them to leave,” and started to get a sense for that.
I’ve also had a number of other occasions where I’ve just been going through people’s profiles and piecing together code words and realised, “Oh! That’s what they’re doing.” It’s very cryptic, going through data at first, but after a certain point there’s sometimes cases that make a lot of sense.
One of the other ones was someone who had been sending me a lot of legal threats. I took a look at his profile, this was a couple of weeks after I had released this, and after the release of ICWATCH there was this article that came out about a programme called Skynet which was using data from telecoms in Pakistan to attract people. I was looking at this guy’s profile and there was a lot of programmes about telephony, then I was looking at his languages and he knew all of the languages that were relevant in Pakistan. And then he mentioned this thing called SEDB, SIGINT Emitter Database, which is one of the databases used in this programme. So I was thinking, “Wow, this is someone who is probably involved in Skynet or a similar programme or knew some of the people involved in Skynet,” something very close to this, so that was surprising to me.
There’s also the ability to look at broader trends. We can figure out the start dates of various programmes and when people start using them more and when they’re succeeded by other programmes, so there’s been some surprising things. For example, the first known mention of XKeyscore was in 2004. It’s possible that this is an error, but it looks like it might not be. So that’s interesting, you can figure out when programmes started and when they end and when they pick up speed.
Similarly we can figure out trends in the intelligence community. I don’t know if there has been a way before to study when people, how many people work in the intelligence community and what they’re working on, at any sort of scale just because it’s so secretive. But when I saw, “Oh these are the positions, or people who mention SIGINT or signals intelligence, I can count the number of people who mention it in any given year.” It goes up and up and up all through the last decade, drops in 2013 and it drops more in 2014, and then it goes right back up in 2015, higher than it was before. So that could’ve been the Snowden effect and then ISIS effect, or just, it bouncing back. It’s interesting to see these trends for the first time.
Much of data in ICWATCH relates to the United States, what is the reason behind this?
A lot of the data in ICWATCH is US focused. I think there are a few reasons for this. One of them could be just our search terms, our search terms were in English and they focus on US surveillance programmes, so that’s going to filter down to US. Second thing is, is that the intelligence contracting in the US is gigantic, probably bigger than most or maybe any other country.
When there’s just a few main contractors, or just a single intelligence agency that people are applying for jobs with, they don’t need to post their resumes online, they can just send it to those places, that’s easy. But when there are several hundred or several thousand or more of these companies that could potentially hire them for their work, then they suddenly need to post this information online to be able to get a job because they don’t have any way to send it in a secure way to many different companies. So I think people have a stronger need to post this information online in the US. Those are probably the main reasons, but there are definitely people in other countries that are mentioned in the data.
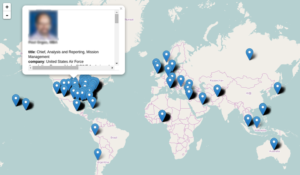
Screenshot taken from the map tool on the Transparency Toolkit website. Taken on 27 November 2015.
There’s one very significant element of the way you curate the data and present it. It’s informed by the fact that you scrape it from LinkedIn, where the focus is on the individual. What drove you to make this choice to focus on the individual rather than institutions?
Initially I started focusing on individuals because individuals were the easiest entry-point because there are many individuals and they’re all posting things about their work online, so that’s the easiest way to start. Though actually in the initial set of data, I had the individual in it, but it was less focused on it than in ICWATCH. I had a network graph, that linked companies to programmes. That is also interesting, but I think there’s been a lot of work looking at intelligence contractors and the programmes themselves, but there’s been less looking at the people involved.
I think that looking at the people involved is extremely important for understanding how institutions function, and why people do what they do because I think that I struggled for a long time to figure out why are people working on these intelligence programmes. Why are people involved in mass-surveillance? Why are people involved in torture and human rights abuses and even worse things? I don’t think people are evil or bad or intentionally try to harm others most of the time. So I found that somewhat perplexing. As a result, I started looking more at the individuals, try to understand why they got involved in the intelligence community and how people view their work and what ethical problems they have, if any, and generally things like that. I think that when we can understand how individuals view the world and their work, we can use that to actually stop problematic programmes. We could use it to provide alternatives to people who might just be interested in a technical challenges, and to actually start an open conversation with the people involved.
Are you driven by the assumption that all intelligence work and all surveillance work is per se bad?
I think that a lot of the work on mass-surveillance is bad or problematic and I think that all of it needs more oversight, even if it’s not bad, and that requires making it public. Making it public doesn’t necessarily say, “This person is working on something bad.” It says that, “this person is working on something that needs accountability and that needs oversight, because it could be bad if it’s being misused.”
What would you say to those who argue that too much transparency does not actually create accountability and instead is aiding the potential enemy?
A lot of people do say that this information can’t be made available for national security reasons or anyone who makes it available is aiding the enemy. I don’t really think that’s the case. I think that there’s some amount that you could gain from knowing what these programmes are, given what we found out from the Snowden revelations alone. We’ve seen that there’s been massive overreach and there’s been misuse of the data that’s been collected and I think that has been far more problematic than any potential risk of this information of somehow giving away methods to the enemy.
It’s so expansive that it’s difficult to avoid surveillance no matter what you do, I don’t think that there’s an easy way to, for any enemy to get around that data, so I don’t think making it public is a major problem. It’s been so secret that not even the people who are supposed to have oversight of these programmes have had full details about their operations, and that’s a major problem too. So when people are not even going through the official channels for accountability properly, we need to take matters into our own hands and find other ways of making that data available so that people can understand what’s going wrong, or if something is going wrong.
Is there a risk of data sources disappearing after you’d published them on ICWATCH?
There’s definitely a risk of data sources disappearing, whenever I release data. So I wait. Sometimes I collect lots of data before I release it. So with LinkedIn, I waited a very long time before releasing it. I released a smaller dataset early on, but before we released lots of data, I waited a long time so I have lots of time to collect it in case it did disappear. That said, the profiles haven’t been disappearing overnight, some of them have gone down, but there’s still quite a few left. It’s still a very useful data source, even a month after releasing ICWATCH.
However, I think that even if LinkedIn did somehow disappear over night, there are lots of open data sources. It’s similar to security vulnerabilities, there’s always more that you can find and exploit. There are other resumes that people post, there’s job listings or social media, there’s government contracts, there’s all of this information that’s just available openly online, and offline information that’s openly available. So over time, it might get harder to collect open data, but we’ll also get better at it, and we can find other resources. When it’s so many people and groups posting this data, there is no centralised way to take it all down quickly.
You are hosted by WikiLeaks right now. What is the link between ICWATCH and WikiLeaks?
Right after we released ICWATCH, it went down. Part of this was due to a bad set up on our end, but it could’ve also been due to a DDoS\ attack. It’s hard to tell if it was just too many people visiting the website or if it was an actual attack. Then we started getting legal threats. So I thought, “Oh well, if there’s a way to dis-incentivise people from trying to get us to take the data down, by making it less possible for us to take the data down, then that’s something we should do.” We talked to WikiLeaks and got it set up on their servers. It’s much harder to try to target us and to get someone’s data removed because there is not a single point of failure. There’s no way that we can just remove everything ourselves. Similarly the data is also in GitHub so people can just clone the data and save it themselves.
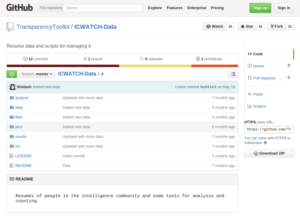
Screenshot from the GitHub repository for ICWATCH taken on 27 November 2015.
Are you worried about the political association with WikiLeaks?
I’m not really that worried about any association with WikiLeaks. It could be problematic, but I don’t mind it that much. I think that it’s a good way to get people not to target us because there is less that we can do when they target us. We have less power to remove data so I think ultimately that’s a good thing.
Do you think there will be some insertion of data to mislead you and others?
Insertion of data is definitely a higher risk than taking the data down, because it’s easier to do in a centralised fashion. There’s definitely a possibility there could be some cases of insertion of data. We did a lot of scraping in advance so it’s possible to detect insertion of data. Although some new data might just be new programmes or changes to existing ones, so it’s hard to be sure. That’s something that we should also try to detect over time.
It could definitely be problematic. But by comparing lots of different sources, not just using LinkedIn, but checking other resume sites and job listings, and matching the jobs to people, it would be a lot more work to insert data and have all of that match up, than it would be to just insert data on LinkedIn. I guess the Intelligence Community probably has the resources to do it, but it definitely will take time and energy to do that.
The dataset you have collected must contain many duplicates, missing data and a lot of noise. How do you go about verification?
The data is definitely incomplete and messy right now. There’s some noise and we have been filtering that out over time. It’s not quite as bad as it could be, because we’ve started using a lot of filtering terms. For example, we ran a list of all the known code words plus SIGINT at the end, so that it at least gets people in signals intelligence, even if it’s not the exact right code word, as it’s a common word that comes up in search results. So that’s helpful for reducing noise. It’s definitely incomplete. There are code words that maybe we didn’t pick up in the right way, and there’s other search terms that we’re still running, so we’re also adding search terms as we’re also removing the noise.
As far as verifying the profiles, it’s difficult to do that in a massive way. A lot of the verification is done in the moments when you’re looking at the profile, and you think, “Oh, that’s interesting. Why don’t I see if I can find this somewhere else, and try to figure out what this is from that.” So a lot of that is just cross-referencing the data manually. Eventually it will be matching that up with other data services automatically in order to verify it.
How do you deal with personal data versus public data?
All the data that we use is public data. Some people have sent us emails saying, “Posting this personal information online threatens my family,” but really mostly we’re using data about people in their professional context. These are resumes, they’re about what people do, and the work that they do. So we have names, and we have pictures, but those are all things that they have posted publicly online already. We found some more personal data manually, that people had publicly on their Facebook profiles, pictures and other information. I avoid finding any identifying information about people’s family members, I stick to the people themselves who have outed themselves online already. While I have general locations, I don’t have precise addresses for people. So we have some boundaries with that, but it’s all based on publicly available information. And there’s even more information you can get publicly. You can get most personal data publicly if people post about it freely enough online.
What is the difference for you between publishing something about the intelligence community and other kinds of profiling of people?
I think that publishing something about the intelligence community versus other kinds of profiling is that when I’m publishing something about the intelligence community and it’s trying to find people who are involved in violations of privacy or even more egregious things like torture or killing people, that’s a very different kind of profiling than profiling people for some other personal attribute. There are some personal attributes that aren’t necessarily a problem, that aren’t necessarily something that people should be blamed for, that aren’t necessarily something that is problematic in any way. But when someone is saying that they’re involved in very ethically problematic, illegal activities, or could be involved in that based on the things that they’re mentioning, I think that’s a very different type of profiling. I think that’s entirely justified. I think in the intelligence community it’s even more so a given to use these techniques as these are the same techniques that they themselves use.
What are your set of tips or bullet points for activists considering what you’ve learned through this process?
If people want to not make their data available, they need to decide what they want available about them online and in what contexts. If people are using social media to post about their work then there is always a risk that people could use it to map them. Either based on the people that they talk to or the people that they’re friends with or the people that they’re following on Twitter or Facebook. There is definitely some potential to be caught up in maps.
You could introduce noise by trying to friend lots of people that you don’t actually know which makes it more complicated to map who you actually know, who you interact with and what you’re working on.
You could avoid posting about anything that you’re really concerned. Take a personal thing that could be legally problematic or could be used against you. Just don’t post about it online. Probably just being very careful with what information you post.
It’s a little bit of a lower risk for having these exact techniques used against activists because people in the intelligence community are frequently working on this in a professional context and trying to get hired by posting about their skills, which most activists are not doing. I see fewer activists posting details about their work that is not public already on social media. There’s definitely more potential for network mapping and combining that with intercepting key information about people’s work. or using that for deciding who to target for intercepting communications. So definitely you should be careful about what you post. And if you’re really worried try to to introduce noise to make it harder to map things.
What are the reactions to ICWATCH?
The reaction at first were actually very good. Lots of people were interested and then fascinated by the methods and approach and that we were even able to use these methods to get interesting data in the first place.
Probably a few days after we launched, I started to get attention from people in the intelligence community. I’m not entirely sure how they were circulating it. My guess was internal mailing lists because I didn’t see many postings about it on social media so it was probably being sent around internally.
A lot of them were very upset to varying degrees. People reacted in many different ways, they were all totally unique reactions. There’s one guy who was very upset and sort of trying to rally against us in the media but no one really paid attention to him. I started getting e-mails from people who were asking me to take down their data, saying that they were concerned that they could be put on a hit list for ISIS and that they might be targeted from that. I got people who were sending me death threats saying that they were going to track me down and kill me. I got people who were sending me legal threats. One guy said that he had this picture on his LinkedIn profile and also his book and he wanted us to remove it within 48 hours, because it was under copyright. He also informed us that he sent a complaint to the FBI that he was trying to press charges for domestic terrorism against us.
I’ve gotten some angry phone calls from people who wanted to tell me that I’m aiding the enemy and I’m stupid and that I’m hurting people. I’ve also received e-mails from people saying that they don’t know why they’re included in the database because they work for a private company and aren’t involved in surveillance or human rights abuses at all. Then I look at their profiles and I see that they were involved in some sort of intelligence agencies several years ago, and now work as a private intelligence contractor. There seems to be this interesting sentiment that if you leave government intelligence and you work for a private contractor that you’re no longer working in the intelligence industry even if you’re directly helping with surveillance programmes. So that’s fascinating.
You are living in Germany now but a lot of the data comes from the United States. What is the difference between the reactions you received from the United States compared to Europe?
Most of the media coverage was in Europe but a lot of that is due to us launching the project here. I’ve talked to some people in the US about it and the reaction has also been mostly good. A few more people who actually work in the transparency space expressed concerns about it. Either about, “Oh. How are you dealing with harm reduction?” anything from that to, “This is horrible and it will hurt our organisation based on you releasing this.” There have been some bizarre concerns. There are more bizarre concerns from people working in the space in the US than in Europe I would say. And a lot of them don’t make a lot of sense, and they seem to think that we release people’s addresses or something like that, which isn’t accurate. I’ve heard of a few more cases of people being more upset. But generally in the US, it has also been quite positive as far as I’ve heard.
What business model do you have for this project?
We don’t really have a business model. It is all non-profit. Right now, we’re just funded based on grants. Eventually, we might try to either do joint grant applications with human rights groups, or journalists, or try to write stories ourselves and pitch them to news organisations. I think largely it will remain grants and donation funded. I thought about working with news organisations and making tools for the datasets that they wanted to use. But a lot of the organisations that can afford to pay for something like that already have programmers and all of them aren’t willing to work on things that are really edgy and really could be useful.
A lot of them are just working on really mundane open government stuff that isn’t really particularly useful. They’re just making some sort of open data portal that you can maybe see, “Okay, this data is interesting,” but it’s harder to see interesting things than in the data that we’re collecting. They aren’t willing to go quite as far and if they were to get legal complaints they would immediately stop. So, I really am not interested in working with a lot of mainstream media organisations on this even if we could use it as a profit model. It just doesn’t seem interesting from my initial explorations into it.
What direction is the Transparency Toolkit going right now?
We’d like to expand to other topics like other intelligence agencies, other issues or other countries and geographical areas. As well as building up additional tools for analysing the data, such as, making a network graph tool hooked into our search results so people can map the search results for a particular search only, similarly with maps and other open data analysis tools.
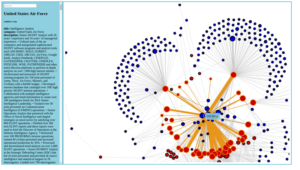
Screenshot from the prototype network graph tool on the Transparency Toolkit website. Taken on 27 November 2015.
Is your new work also focusing on this specific kind of public data?
Yes, all of our work is still focusing on open data. That is our primary focus. We use other types of public data to come up with search terms. We heavily used the Snowden documents to come up with the search terms for ICWATCH. This would probably not have been possible without the Snowden documents. We knew these code words before so we could put in known contractors and start finding code words. But it would be much harder to get the context around the new code words without knowing a few already. So that was great. We used leaked documents and also publicly released documents. We’ll probably continue to do that and to find ways to combine that information but our primary focus is on open data and things that can be collected with open data that we might not be able to find with those other methods.
With these publications, you’ve become one of the people who is enabling a lot of other groups, non-profits and NGOs, to access information they couldn’t. What do you think this mass publication of public data, with much better interfaces, is helping with?
It depends on what the data is. Two of the general uses that come to mind are: Firstly, a more journalistic approach, writing articles and piecing together interesting information. For example, finding new code words and revealing what they do and talking about that publicly in an easier to understand fashion. Also finding people who are involved in things and actually talking to them and trying to understand why they’re involved.
The second one is a legal approach. It’s possible to find people who are involved in mass surveillance programmes and in torture programmes and to use the information available on their profiles to potentially build legal cases either against them or against the organisations that they’re involved in. I think that could also be a particularly effective and interesting approach.
Then there are other more topic specific things that depend on what is going on.
Do you have a dilemma that this work, besides exposure, can also normalise certain practices within this community because they become known. We know, for example with the Snowden documents, that there’s not as much happening after this information is released. So, it becomes somewhat codified and people become desensitised to it.
One of the things that I think is particularly powerful about focusing on individuals rather than institutions is that when the Snowden documents came out, people were shocked at first. But eventually, over time, people became complacent and they started to think, “Oh, this is such a big problem. I can’t do anything about it. It’s up to people who are lobbying Congress or in legal cases, or making privacy tools. I can’t do anything about it.” That’s what a lot of people seem to think.
When we can bring it down to the individual level and we can say, “These are the people who are involved in these things. You have the same friends or you went to the same school or you grew up in the same town.” When we can provide ways for people to identify with these bigger issues on a personal level and see how they’re connected to them. That brings it from a big problem that’s a problem for someone somewhere else to something that affects them personally that they can think about it in a context that is more manageable. So I think there could be a problem that people say, “Oh, this is interesting but there’s not anything I could do,” or others say, “This is something we know but it’s not something we can do anything about.” But I think it has the potential to help people identify with the data and use it in a different way than data released by governments or by whistle-blowers.”
When people look into the history of abuse of power, on one side of the spectrum you have those who are trying to look at the chain of command. The other side of the spectrum is where you are, which is where the grey individual, who is just following the rules and is creating a system that is evil. So the banality of it is there. How do you see yourself within the spectrum?
A lot of people think that only the decision makers, the people in power, should be held to account. I don’t think that’s the case, because institutions are made up of people and the people who aren’t decision makers aren’t mindless drones either. They have a lot of power to change things, to complain, to stop doing what they are doing and I think they should be using that power. I don’t think that they, or even the decision makers should be demonised and have all the blame placed on them. But I think that people should be held accountable for their role in institutions even if it is just perpetuating a broken and horrible system that needs to be public. Especially when it is something like surveillance that affects so many people all over the world. I think that everyone should be held accountable to a certain degree, but I don’t think that anyone should be demonised and have all the blame placed on them.
There is a paradox in your work which makes it even more interesting. The funding that is enabling you to do this work is coming from somebody who founded the company that is actually one of the top intelligence gathering companies in the world, Palantir. How do you feel about this paradox?
One of the ways that we’re funded is via the Thiel Fellowship which is founded by Peter Thiel who also founded Palantir. Palantir does a lot of work creating analytics tools for the intelligence community. But I don’t really have any interaction with him. It’s interesting and I’ve worried for a while about other people’s reactions to me being funded by something like that. I don’t particularly feel bad about being funded by someone who started Palantir since they don’t have any control or influence.
It’s a little bit a of paradox, it’s a little bit strange but we haven’t ever had anyone from that community try to influence our work. We’ve collected data on Palantir along with every other intelligence contractor. I have never met Peter Thiel as he doesn’t directly choose the Thiel Fellows. It’s a different group of people at the Thiel Foundation that chooses the Fellows, so it was more their decision and I think it was more based on their priorities. Actually the first time I applied, I didn’t get the fellowship but I don’t think that was based on any political or ethical reasons. I think that was mostly based on the fact that I wasn’t this far along when I first applied.
As long as people aren’t trying to control my work or use it for unethical purposes or things like that, I am okay with that.
Your work is centered around data. Do you think we’re living in a data society that has its own set of new rules? And how do you think this impacts activism?
All the data that people are making publicly available definitely provides a huge opportunity that we haven’t had before to understand the institutions or create our own accountability mechanisms. We don’t need to rely on institutions or go and talk to people and say, “We need this data.” We can say, “Oh, we can go find this data ourselves” and have that accountability mechanism ourselves. So, I think that yes, there’s some amount of rethinking of activism that we should do to try to build sousveillance
Sousveillance, in comparison to surveillance, refers to the act of ordinary people ‘watching from below’ usually with portable recording devices. The term was coined by Steve Mann and comes from the French word ‘sous’ which means from below rather than ‘sur’ which translates as ‘above’.
sousveillance states and try to build in our own accountability mechanisms based on all the data that is publicly available.
You are in Berlin while there is a big hype around the city, a so-called ‘hackers heaven’. How did you come to be in Berlin?
I moved to Berlin because there was a good community of people working on interesting stuff. At the time, I was living in the Bay Area and there’s a lot of start-up people there. I really don’t like start-up people. I wanted to get away from the whole start-up culture in the Bay Area. I’m not initially from there, so I was actually a little bit lonely when I was living there. I’m from Boston, but I don’t want to go back there because it’s very much a college town and I wasn’t in school, I wasn’t involved in research any more, so I didn’t feel like I wanted to be there. I kept coming out to Berlin for conferences and I kept wanting to stay here. I started spending a lot of my time here so I thought why don’t I just move here. It’s probably the best place to be for what I’m doing at this moment
Part C: Comments to 1): 2015 – M. C. McGrath: Watching the Watchers: Building a Sousveillance State
@terrencemckenna
8 years ago
Great talk on a very interesting topic, thanks M.C.
Who’s the audience member who asked 2 questions (in glasses)? I recognize his face, the host calls him by “Jake” but I can’t put my finger on who it is.
@psuplat
8 years ago
On the other hand some of those “watchers” are simply doing their jobs to provide a life for their families and a decent future for their children. Should they deserve to be publicly “named and shamed”? I don’t think so.
I don’t care if my LinkedIn profile is publicly available – it’s just my professional life (not private) and may lead to better job opportunities. However, it does bother me that by a use of the wrong word I could end up on the ICwatch site and what fallout that would have?
Finally, there is the internet – you have to be toddler-naive thinking there is anonymity in the internet or ever was for that matter. And is it really that different from the ‘good old times’ when someones could just as easily peel open an envelope, read the content and neatly put it back in?
As communications evolved throughout the centuries, so did the tools for it’s interception by less than kind people. It’s the never-ending struggle of god and evil, tilting at windmills, call it what you like, but it will never end.
As for the McGrath kid – extremely smart, but maybe he should apply his brains to solving other problems, rather that the said “tilting at windmills”
@coryryder9070
8 years ago
2008 I started pushing for afew idea’s to help things titled OPM-our Planet Peace people matter 1 alternative powered farming resources 2 a non-social pro network for public gov and business that was taken turned into teaparty to twitter to crowdrise and linked in 3 Public Options bundle deal like net phone cable but nessesities help keep things affordable for those who need the help and much more who you mention just shows there is an agenda atleast between all the social media propaganda
@airbornelib
8 years ago
So how is it he is flashing SECRET data and not arrested?
@coryryder9070
8 years ago
or the guy got “laid off” and then found a job at mazda?
@coryryder9070
8 years ago
ever see truth may scare you and others in my favs list ?
@williamhudson1279
4 years ago
24:51 that blonde babe
@airbornelib
8 years ago
Well as usual, after watching this video, he is uninformed and quite frankly, does not know what he is talking about.
@halcontv
8 years ago
@metoo924
6 years ago (edited)
I know that patriots fought for this country so that you have the right to create these type of programs, but do you not realize that you are capitalizing on people who protect you and protect the US everyday? They do it behind closed doors, in locked down buildings, in places you will never go. But rest assured, even when you reveal who they are, show their homes and families (THAT IS JUST IRRESPONSIBLE), they will continue to protect America’s interest. It makes me sick to know that you are ‘outing’ them like this…Why? They protect you and your family, why won’t you protect them and their families?
___________________________________________
Part D. * The “Cryptocracy” (rule by secrecy) is accurately identified as the CIA in Walter Bowart’s “Operation Mind Control: The CIA’s Plot Against America” (1978).
“The Hidden Hand” is accurately identified as world Judaism in “The Secret World Government or “The Hidden Hand” by Maj.-Gen. Count Cherep-Spiridovich (1926).
The power behind “The Hidden Hand” is accurately identified as the “London Money Power”/”Jew Money Power” by Woolfolk (1890) in “The Great Red Dragon Or London Money Power.” (See: Corrected History: (London) “Jew Money Kings,” Nazi Cartels, The Protocols, Zio-nazis, “Anti-Semitism,” American Traitors, and Illuminati Families).
And since “he who pays the piper, calls the tune,” the covert operatives mentioned below who carry out these global organized stalking-electronic torture black ops are merely paid killers, “pawns in the game” of the “World Revolutionary Movement,” as per Canadian Naval Commander, William Guy Carr’s book, “Pawns in the Game” (1956).
** “America’s interest.” Webmaster comment: And who defines “America’s interest?” Could it be, for example, the international bankers, the “corporatocracy,” or the Committee of 300 or their legions of minions in the CFR, CIA, NSA, UN, WEF, the Intelligence Community, and National Security Racketeering Network? It certainly is not the American people. In this regard, it has been well understood for over half a century that “national security” is a euphemism for “security of the elite-business sector that rules America.”
Comments (0)